
27. 实现 GPT 多头注意力层#
27.1. 介绍#
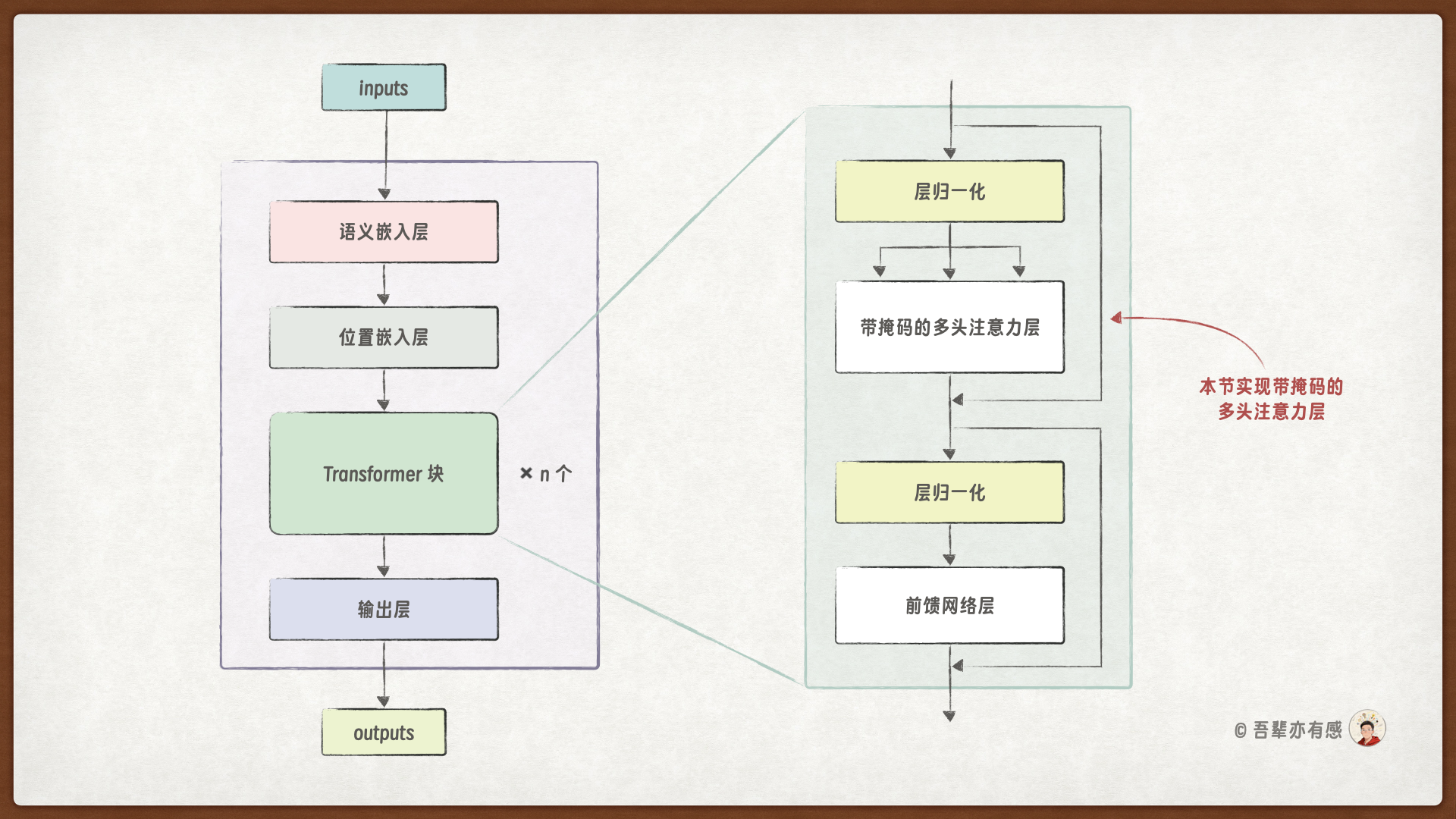
上一节我们已成实现 Transformer 块的层归一化组件,本小节将继续实现 Transformer 块的多头注意力层。
27.2. 环境配置#
27.2.1. 安装依赖#
!pip install --upgrade dsxllm
27.2.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
27.3. 带掩码多头注意力层#
在 GPT 中,带掩码的多头注意力层(Masked Multi-Head Self-Attention)是其核心组件之一,负责捕捉序列内部的依赖关系,同时确保生成过程是自回归的——即每个位置只能依赖于它之前的位置,不能“看到”未来的信息。
27.3.1. 自注意力机制#
首先,标准的缩放点积自注意力(Scaled Dot-Product Self-Attention)允许序列中的每个位置与序列中的所有其他位置进行交互,计算注意力权重,从而聚合全局信息。公式如下:
其中,\(Q, K, V\) 分别是通过输入嵌入与权重矩阵相乘得到的查询、键和值矩阵。对于长度为 \(n\) 的序列,注意力矩阵 \(QK^T\) 的大小为 \(n \times n\),元素 \((i, j)\) 表示位置 \(i\) 对位置 \(j\) 的注意力分数。经过softmax后,每个位置会聚合所有位置的值。
27.3.2. 多头注意力机制#
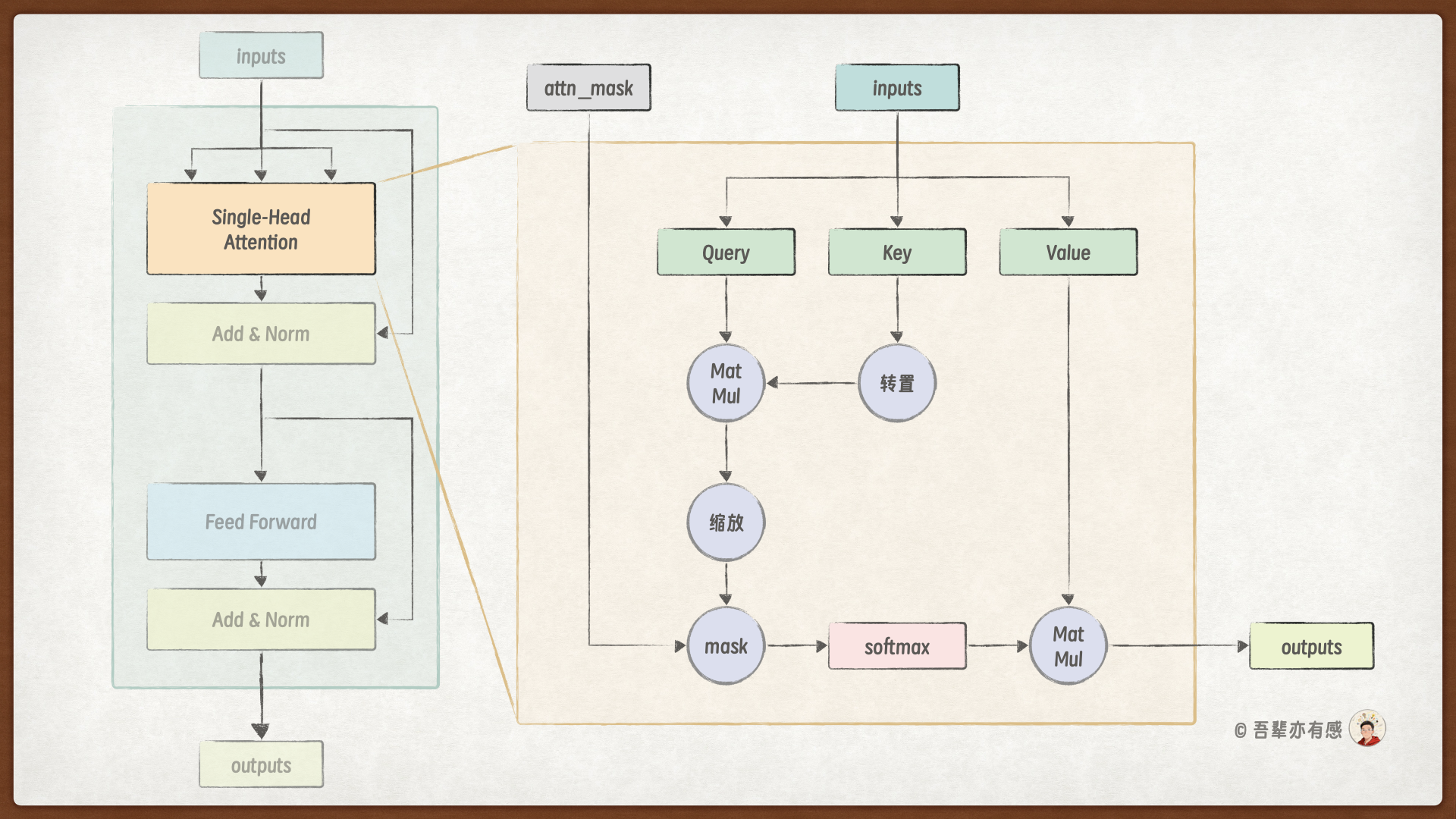
多头注意力机制(Multi-Head Attention)通过并行计算多个注意力头,每个头关注序列中的不同子空间,从而捕捉到不同类型的依赖关系。在学习多头注意力详细的计算过程之前,我们先回顾一下标准的单头自注意力机制计算细节。
单头注意力层的计算图如下所示:
多头注意力 是指将查询、键、值分别投影到 head 个不同的低维空间(称为“头”),然后在每个头上独立地执行注意力计算,最后将所有头的结果拼接并投影回原始维度。这样做的好处是:
捕捉不同类型的依赖关系:不同的头可以关注序列中不同位置的关系(例如,语法关系、长距离依赖、局部关系等)。
增强表达能力:通过多个头,模型可以从多个角度理解序列,提升表示能力。
虽然在 GPT 中,每个头虽然独立地进行自注意力计算,但是每个头的Q、K、V矩阵都是从原始输入通过一个大的线性变换得到的,然后再将大的Q、K、V矩阵分别切分成多个小的Q、K、V矩阵。这样做的好处是,将多个小矩阵的计算转换成了一个大矩阵的计算,可以充分利用 GPU 并行计算的能力,提高计算效率。
所以,多头注意力层的计算图如下所示:
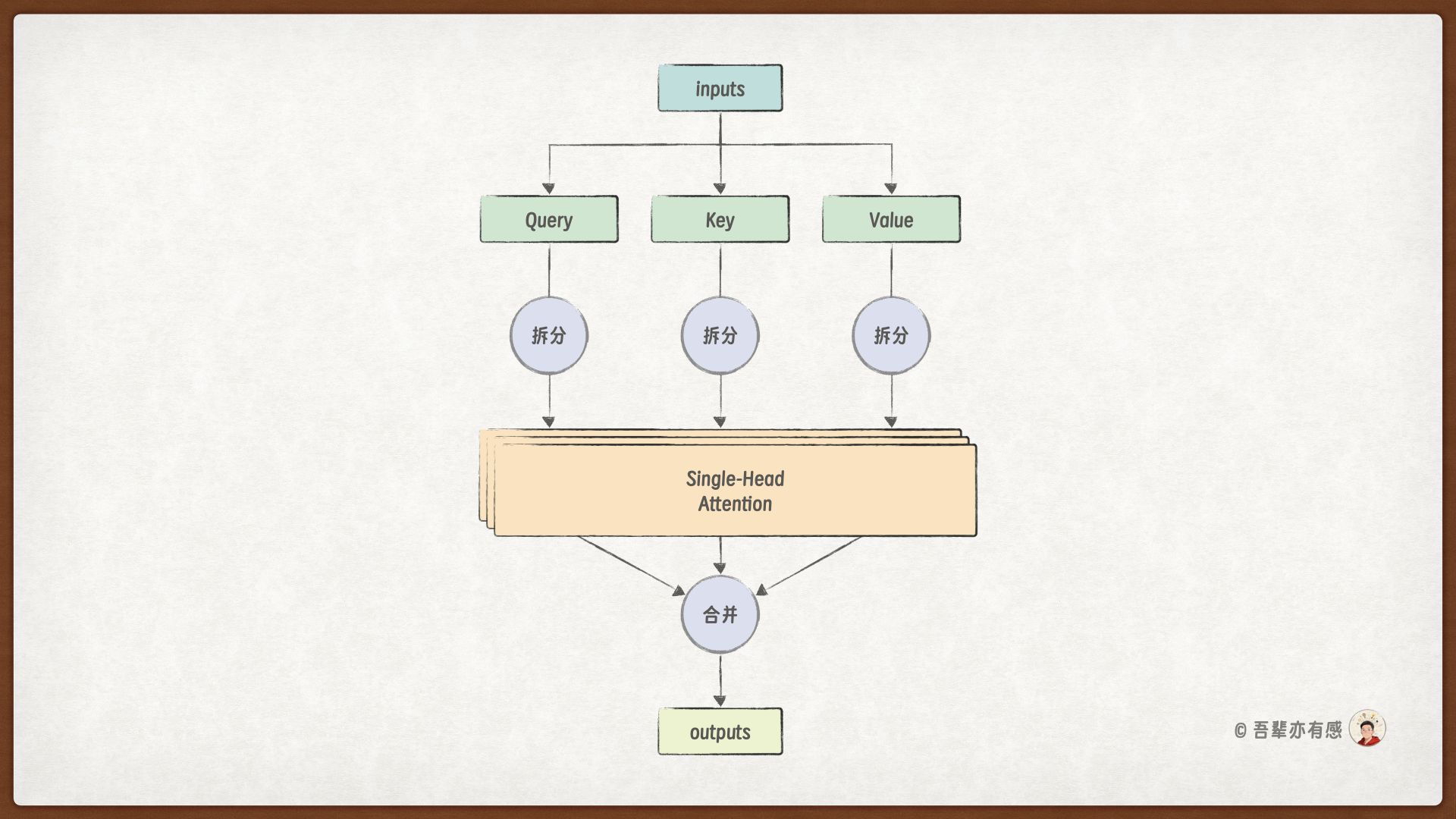
进行多头注意力计算时,有两个额外的拆分和合并操作:
拆分操作:将大的Q、K、V矩阵分别切分成多个小的Q、K、V矩阵,每个小矩阵的大小为
head_dim。合并操作:将多个头的输出拼接起来,将拼接后的矩阵再通过一个线性变换融合信息,就得到最终的多头注意力输出。
27.3.3. 因果注意力掩码#
在 GPT 这样的自回归语言模型中,目标是预测下一个词,因此生成时必须确保当前位置不能访问未来位置的信息。否则,模型会“作弊”,导致训练和推理不一致。这里使用的掩码是因果注意力掩码,它的作用是在计算注意力时,将未来位置的信息屏蔽掉。
掩码的作用就是在计算注意力权重时,将未来位置的注意力分数设置为负无穷(通常用 −∞ 或一个非常大的负数),使得经过softmax后这些位置的权重变为0。这样,每个位置只能关注它自己和之前的位置。
在GPT这样的自回归语言模型中,目标是预测下一个词,因此生成时必须确保当前位置不能访问未来位置的信息。否则,模型会“作弊”,导致训练和推理不一致。这里使用的掩码是因果注意力掩码,它的作用是在计算注意力时,将未来位置的信息屏蔽掉。
掩码的作用就是在计算注意力权重时,将未来位置的注意力分数设置为负无穷(通常用 −∞ 或一个非常大的负数),使得经过softmax后这些位置的权重变为0。这样,每个位置只能关注它自己和之前的位置。
以输入序列 动手学大模型 为例,使用因果注意力掩码的过程如下所示:
序列长度为 6,则其对应的注意力矩阵为:
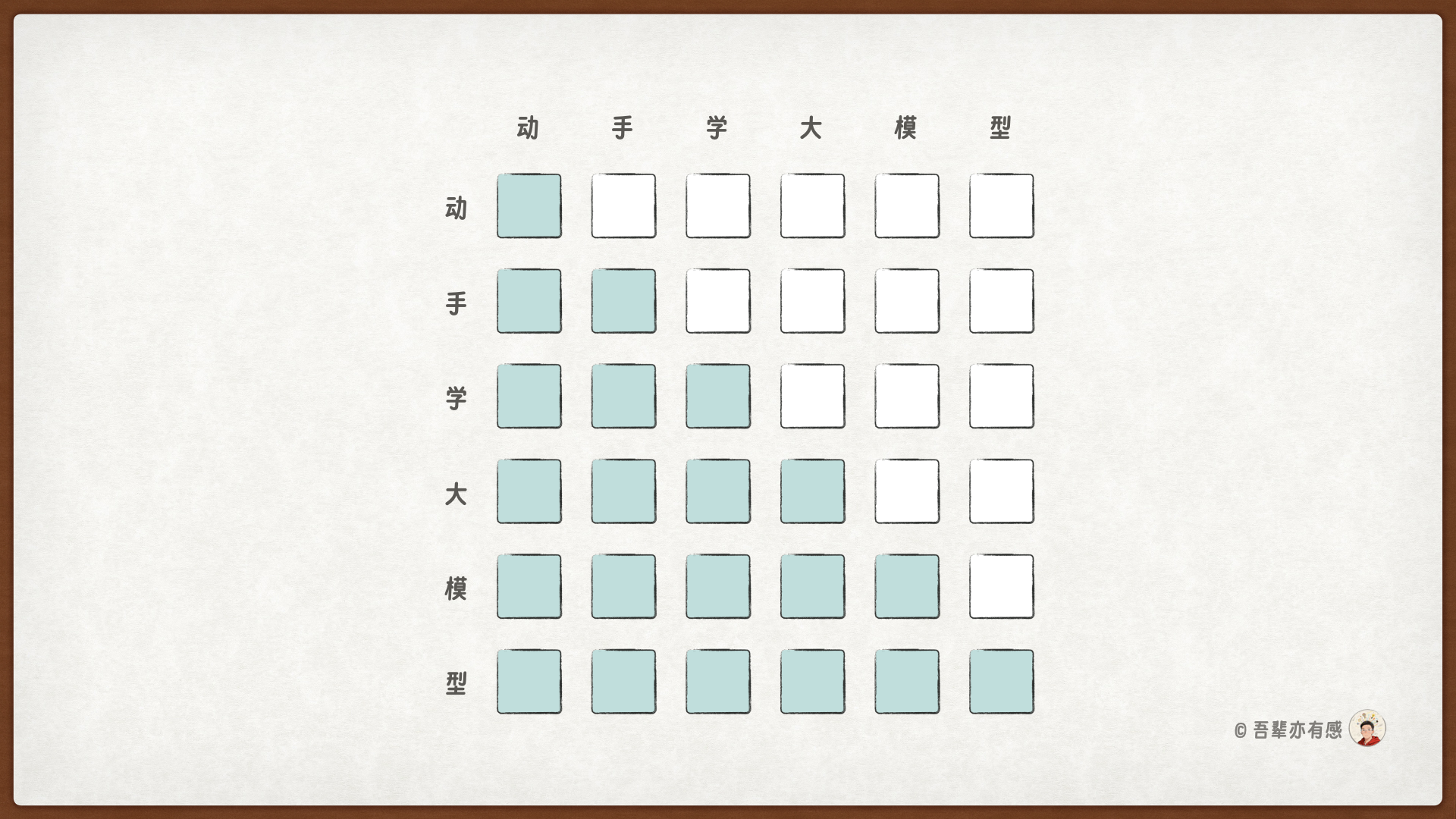
假设每个 Token 之间自注意力得分矩阵为:

应用因果注意力掩码,将未来位置的注意力分数设置为负无穷:

使用 softmax 计算注意力权重,掩码位置的权重为 0:

27.4. 带掩码多头注意力层的代码实现#
import torch
from dsxllm.util import print_red
class MultiHeadAttention(torch.nn.Module):
"""
多头自注意力模块。
Args:
input_dim (int): 输入特征维度。
output_dim (int): 输出特征维度(必须能被 num_heads 整除)。
context_length (int): 最大序列长度,用于生成因果掩码。
dropout (float): Dropout 概率。
num_heads (int): 注意力头的数量。
qkv_bias (bool): 是否在 Q、K、V 线性投影中使用偏置。
"""
def __init__(
self, input_dim, output_dim, context_length, dropout, num_heads, qkv_bias=False
):
super().__init__()
assert output_dim % num_heads == 0, "output_dim must be divisible by num_heads"
self.output_dim = output_dim
self.num_heads = num_heads
self.head_dim = output_dim // num_heads # 每个头的维度
# 定义查询、键、值的线性层
self.query_layer = torch.nn.Linear(
in_features=input_dim, out_features=output_dim, bias=qkv_bias
)
self.key_layer = torch.nn.Linear(
in_features=input_dim, out_features=output_dim, bias=qkv_bias
)
self.value_layer = torch.nn.Linear(
in_features=input_dim, out_features=output_dim, bias=qkv_bias
)
# 定义输出层
self.output_layer = torch.nn.Linear(
in_features=output_dim, out_features=output_dim
)
self.dropout = torch.nn.Dropout(dropout)
# 因果掩码:上三角矩阵,用于屏蔽未来位置的注意力
# 注册为缓冲区,不会作为模型参数更新,但会随模型移动
self.register_buffer(
"mask", torch.triu(torch.ones(context_length, context_length), diagonal=1)
)
def forward(self, x):
"""
前向传播。
Args:
x (torch.Tensor): 输入张量,形状为 (batch_size, seq_len, input_dim)。
Returns:
torch.Tensor: 输出张量,形状为 (batch_size, seq_len, output_dim)。
"""
batch_size, seq_len, _ = x.shape
# 1. 通过线性层得到 Q、K、V,形状为 (batch_size, seq_len, output_dim)
queries = self.query_layer(x)
keys = self.key_layer(x)
values = self.value_layer(x)
# 2. 将 Q、K、V 拆分为多头,重塑为 (batch_size, seq_len, num_heads, head_dim)
queries = queries.view(batch_size, seq_len, self.num_heads, self.head_dim)
keys = keys.view(batch_size, seq_len, self.num_heads, self.head_dim)
values = values.view(batch_size, seq_len, self.num_heads, self.head_dim)
# 转置为 (batch_size, seq_len, num_heads, head_dim) ➡️ (batch_size, num_heads, seq_len, head_dim)
# 这一步是为了将序列长度维度和头维度交换,方便后续的分头进行自注意力计算
queries = queries.transpose(1, 2)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
# 3. 使用矩阵计算缩放点积注意力分数,keys 转置最后两维:(batch_size, num_heads, seq_len, head_dim) ➡️ (batch_size, num_heads, head_dim, seq_len)
# 在PyTorch中,当使用 @ 运算符(或 torch.matmul 函数)进行矩阵乘法时,会自动处理批量维度并对最后两个维度执行标准矩阵乘法
# 这一步计算的是每个头的注意力分数,形状为 (batch_size, num_heads, seq_len, seq_len)
attention_scores = queries @ keys.transpose(-2, -1)
print_red("\n1. 注意力分数:")
print(attention_scores)
# 4. 应用因果掩码(屏蔽未来位置)
# 将原始掩码截断到当前序列长度,并转换为布尔类型,布尔类型张量比浮点数或整数类型占用更少的内存(每个元素 1 字节),这使得它在处理大规模数据时更加高效。
causal_mask = self.mask.bool()[:seq_len, :seq_len]
attention_scores.masked_fill_(causal_mask, -torch.inf)
print_red("\n2. 应用因果掩码后的注意力分数:")
print(attention_scores)
# 5. 计算注意力权重(softmax)并应用 dropout
attention_weights = torch.softmax(
attention_scores / (self.head_dim**0.5), dim=-1
)
print_red("\n3. 应用因果掩码后的注意力权重:")
print(attention_weights)
attention_weights = self.dropout(attention_weights)
# 6. 加权求和得到上下文向量,形状为 (batch_size, num_heads, seq_len, head_dim)
context = attention_weights @ values
# 7. 合并多头输出
# 先转置为 (batch_size, num_tokens, num_heads, head_dim),然后重塑为 (batch_size, num_tokens, output_dim)
context = context.transpose(1, 2).contiguous()
context = context.view(batch_size, seq_len, self.output_dim)
# 8. 输出投影(可选)
output = self.output_layer(context)
return output
/Users/kong/opt/anaconda3/envs/dsx-ai/lib/python3.12/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
27.5. 带掩码多头注意力层的应用实例#
batch_size = 1
seq_len = 6
input_dim, output_dim, dropout, num_heads = 4, 4, 0.1, 2
# 创建输入数据
x = torch.randn(batch_size, seq_len, input_dim)
print("\n多头自注意力层最初输入的数据形状:\n", x.shape, "\n")
# 初始化多头自注意力层
multi_head_attn = MultiHeadAttention(input_dim, output_dim, seq_len, dropout, num_heads)
print("多头自注意力层:\n", multi_head_attn, "\n")
# 使用多头自注意力层进行计算
context_vec = multi_head_attn(x)
print("\n多头自注意力层最终输出的数据形状:\n", context_vec.shape)
多头自注意力层最初输入的数据形状:
torch.Size([1, 6, 4])
多头自注意力层:
MultiHeadAttention(
(query_layer): Linear(in_features=4, out_features=4, bias=False)
(key_layer): Linear(in_features=4, out_features=4, bias=False)
(value_layer): Linear(in_features=4, out_features=4, bias=False)
(output_layer): Linear(in_features=4, out_features=4, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
1. 注意力分数:
tensor([[[[-1.9254, 0.5550, 0.0929, -0.0293, 0.5207, -1.0635],
[ 0.6581, 0.2271, -0.2832, 0.8665, -1.7912, -0.1338],
[-0.3595, -0.0062, 0.0836, -0.2311, 0.5223, -0.0676],
[-0.4889, 0.2849, -0.0633, 0.2884, -0.4250, -0.4419],
[ 1.0251, -0.5967, 0.1322, -0.6032, 0.8883, 0.9255],
[-1.6281, 0.1580, 0.2664, -0.6645, 1.6453, -0.5279]],
[[-0.0861, -0.3119, 0.1356, -0.1364, 0.3260, 0.2548],
[ 0.4471, -1.1365, 0.2674, -0.1142, 0.2327, 1.0212],
[-0.1740, 0.1345, 0.0044, -0.0474, 0.1245, -0.1356],
[-0.7856, 0.1128, 0.1942, -0.3616, 0.9074, -0.1919],
[ 1.2710, -0.0874, -0.3478, 0.6135, -1.5345, 0.2295],
[-0.4169, 0.4893, -0.0483, -0.0637, 0.1815, -0.4671]]]],
grad_fn=<UnsafeViewBackward0>)
2. 应用因果掩码后的注意力分数:
tensor([[[[-1.9254, -inf, -inf, -inf, -inf, -inf],
[ 0.6581, 0.2271, -inf, -inf, -inf, -inf],
[-0.3595, -0.0062, 0.0836, -inf, -inf, -inf],
[-0.4889, 0.2849, -0.0633, 0.2884, -inf, -inf],
[ 1.0251, -0.5967, 0.1322, -0.6032, 0.8883, -inf],
[-1.6281, 0.1580, 0.2664, -0.6645, 1.6453, -0.5279]],
[[-0.0861, -inf, -inf, -inf, -inf, -inf],
[ 0.4471, -1.1365, -inf, -inf, -inf, -inf],
[-0.1740, 0.1345, 0.0044, -inf, -inf, -inf],
[-0.7856, 0.1128, 0.1942, -0.3616, -inf, -inf],
[ 1.2710, -0.0874, -0.3478, 0.6135, -1.5345, -inf],
[-0.4169, 0.4893, -0.0483, -0.0637, 0.1815, -0.4671]]]],
grad_fn=<MaskedFillBackward0>)
3. 应用因果掩码后的注意力权重:
tensor([[[[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5756, 0.4244, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2738, 0.3516, 0.3746, 0.0000, 0.0000, 0.0000],
[0.1720, 0.2974, 0.2325, 0.2981, 0.0000, 0.0000],
[0.3254, 0.1034, 0.1730, 0.1029, 0.2954, 0.0000],
[0.0442, 0.1563, 0.1687, 0.0873, 0.4473, 0.0962]],
[[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.7539, 0.2461, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2960, 0.3682, 0.3358, 0.0000, 0.0000, 0.0000],
[0.1603, 0.3027, 0.3206, 0.2164, 0.0000, 0.0000],
[0.4054, 0.1551, 0.1291, 0.2547, 0.0558, 0.0000],
[0.1255, 0.2381, 0.1628, 0.1610, 0.1915, 0.1211]]]],
grad_fn=<SoftmaxBackward0>)
多头自注意力层最终输出的数据形状:
torch.Size([1, 6, 4])
27.6. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。